




Data Analyst
Le Data Analyst transforme des données brutes en indicateurs exploitables pour aider une organisation à décider, prioriser et piloter sa performance. Une formation Data Analyst sert souvent de tremplin pour structurer une méthode de travail, consolider les bases statistiques et prendre en main des outils de reporting utilisés au quotidien.
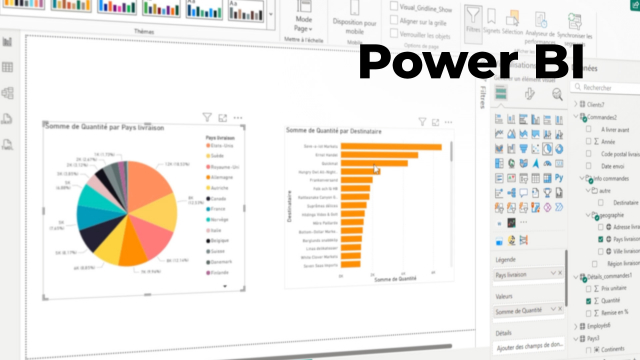
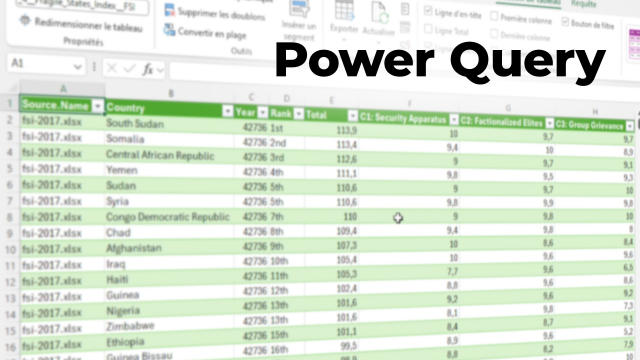
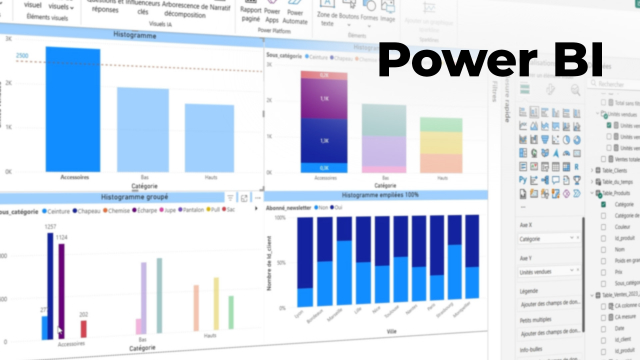
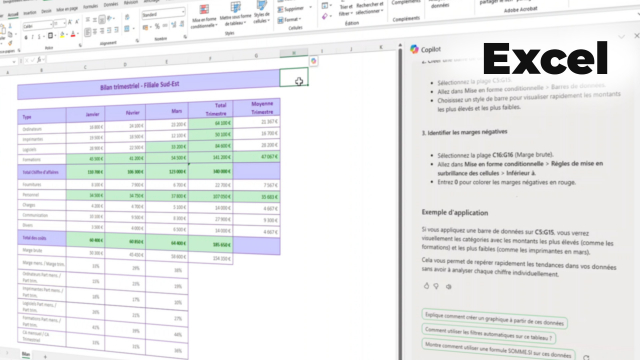
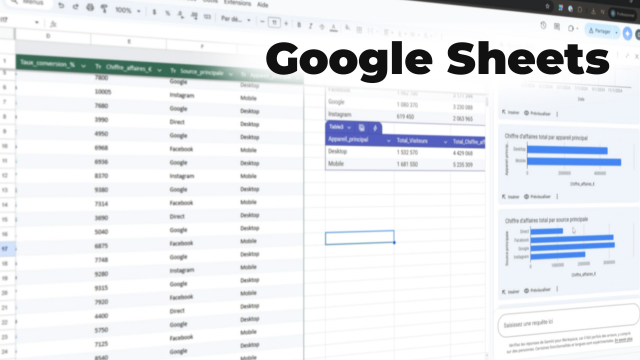
Dans la pratique, le métier combine l’analyse, la qualité de la donnée et la restitution : préparation des jeux de données, calcul d’indicateurs, exploration des tendances, puis création de tableaux de bord et de rapports. Les environnements de travail s’appuient fréquemment sur Excel et Power BI, avec un enjeu permanent : Analyser un jeu de données sans perdre le fil du besoin métier.
Pour se former en vidéo à son rythme, Elephorm propose un modèle d’apprentissage asynchrone, avec accès illimité par abonnement, formateurs experts, fichiers d’exercices quand pertinent et certificat de fin de formation.







