
Automatiser la génération et l’enrichissement de leads avec n8n et l’IA





Détails de la leçon
Description de la leçon
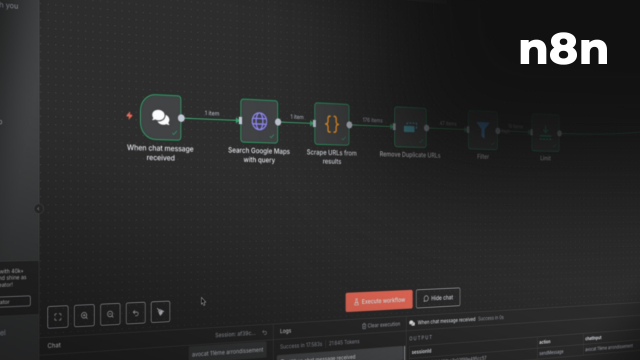
Dans cette leçon, nous vous montrons comment concevoir une machine de génération de leads efficace en exploitant Google Maps et des techniques avancées de scraping. Tout d'abord, nous utilisons un chat node trigger pour capturer les requêtes d'entrée qui seront ensuite explorées à l'aide d'une API Google Maps. En utilisant des méthodes comme le scraping de code HTML et l'extraction de données pertinentes grâce aux fonctions REGEX, vous apprendrez à structurer les informations récoltées sous forme d'URL et de numéros de téléphone.
Ce processus inclut également des techniques de filtrage avancé pour supprimer les doublons et se concentrer uniquement sur les leads pertinents. Pour enrichir les leads obtenus, nous appliquons des expressions régulières avancées pour extraire les emails et les numéros de téléphone, avant de regrouper ces données pour une utilisation optimisée.
Objectifs de cette leçon
Les objectifs de la vidéo sont de guider les utilisateurs dans la création d'une machine de génération de leads en utilisant le scraping et de les instruire sur la transformation de données brutes en informations exploitables.
Prérequis pour cette leçon
Une connaissance de base en programmation, notamment en languages utilisant les expressions régulières et des compétences en analyse de données sont nécessaires.
Métiers concernés
Les analystes de données, les spécialistes en marketing digital, et les développeurs Business Intelligence peuvent tirer parti de ces techniques pour optimiser leurs processus de génération de leads.
Alternatives et ressources
En lieu et place de Google Maps, des alternatives telles que Bing Maps ou OpenStreetMap peuvent être explorées pour des besoins similaires.
Questions & Réponses
